Mono on PowerPC 64
As part of SUSE 11, Mono needs to run on the PowerPC in 64 bit mode. The effort was bootstrapped with some early work from Andreas Faerber.
It was fun to watch Mark's daily commits progress of the port, the tests referenced here are the basic runtime tests that we use to check for regressions and to get a port up and running, it is a good roadmap for how a port comes to life:
* mini-ppc64.c, cpu-ppc64.md: Fixed some opcodes. PPC64 passes basic.exe now. --- * cpu-ppc64.md: Fixed a few instruction lengths. * mini-ppc64.c: Don't emit SETLRET. Now PPC64 passes basic-float.exe. --- * decompose.c: Decompose carry and overflow add on PPC64 like on other 64 bit archs. Don't decompose sub at all on PPC64. * mini-ppc64.c, exceptions-ppc64.c, tramp-ppc64.c, cpu-ppc64.md: Several fixes and new opcodes. Now PPC64 runs (but doesn't pass) basic-long.exe. --- * ppc/ppc-codegen.h: Use ppc_load_reg instead of ppc_ld in ppc_load_func to fix the 2 bit shift. --- * mini-ppc64.c, mini-ppc64.h, cpu-ppc64.md: Several fixes. Now PPC64 passes basic-long.exe. --- * ppc/ppc-codegen.h: Make ppc_is_[u]imm16() work with 64 bit values. --- * mini-ppc64.h, cpu-ppc64.md: Fixed caller/callee saved floating point regs. Now PPC64 passes basic-calls.exe. --- * mini-ppc64.c, mini-ppc64.h, exceptions-ppc64.c, tramp-ppc64.c, cpu-ppc64.md: Several fixes. PPC64 now runs objects.exe. --- * mini-ppc64.c, tramp-ppc64.c: Small fixes. PPC64 now runs arrays.exe and basic-math.exe. --- * mini-ppc64.c, mini-ppc64.h, exceptions-ppc64.c, cpu-ppc64.md: Several fixes. PPC64 now runs exceptions.exe and devirtualization.exe. --- * mini-ppc64.c: Several fixes. PPC64 now runs iltests.exe. --- * mini-ppc64.c, mini-ppc64.h, tramp-ppc64.c: Disable generic code sharing. PPC64 now passes generics.exe. --- * basic-long.cs: New test case. --- * mini-ppc64.c, mini-ppc64.h, tramp-ppc64.c, cpu-ppc64.md: Several fixes. PPC64 now passes most of the runtime regressions.
Followed by today's tweet:
The bootstrap means that the Mono JIT is actually doing a full build of Mono's compilers and class libraries and can be built on the target platform.
Update: Mark has posted a great picture of Jim Purbrick from Second Life, the man behind Mono running on Second Life.
Posted on 25 Nov 2008
Unity on Linux, First Screenshots
The first Unity3D on Linux screenshot:
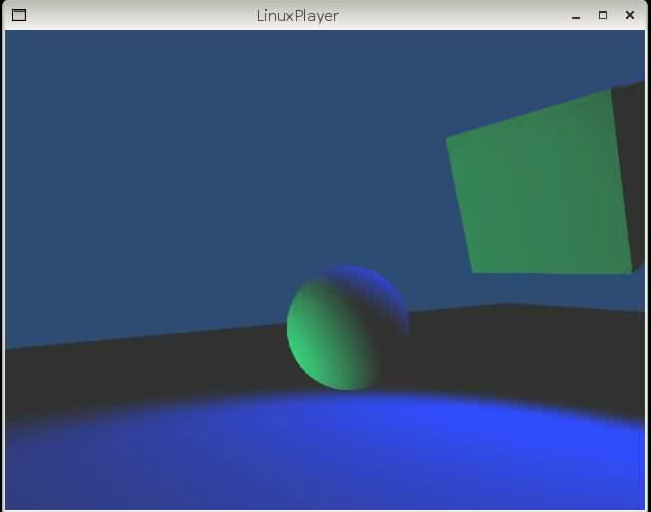
The above program was built on MacOS, the result copied to Linux and then executed using the LinuxPlayer. This is still very basic, the port is yet far from done.
I followed Joachim's advise and added a tiny script to update the cube on the screen. See the video of the cubes in action: ogg and wmv.
Posted on 14 Nov 2008
Framework Design Guidelines, 2nd Edition
 A couple of years ago I wrote
an enthusiastic
review of Brad
Abrams
and Krzysztof
Cwalina's Framework
Design Guidelines, a book that I absolutely love.
A couple of years ago I wrote
an enthusiastic
review of Brad
Abrams
and Krzysztof
Cwalina's Framework
Design Guidelines, a book that I absolutely love.
The book is a great compendium of best-practices for building software, traps and pitfalls to avoid.
But most importantly, it is the best source to learn the idioms and patterns used in the .NET Frameworks. Learning these idioms will have you writing code like the native C# speakers in no time.
I was incredibly honored when Brad asked me earlier this year to write the foreword for the second edition of the Framework Design Guidelines.
The second edition tracks the evolution of .NET and they apply as well to Mono. For instance, it now contains LINQ design patterns, extension methods patterns and DependencyProperties (used in WPF and Silverlight).
Posted on 13 Nov 2008
Silverlight Toolkit, now MS-PL
Update: Fixed some links, corrected some text.
Shawn Burke announced the Silverlight Toolkit and it is licensed under the open source MS-PL. The code is available here complete with unit tests (check Ning's blog on the unit testing framework).

With the Silverlight Toolkit they are taking a new approach to shipping new controls in an effort to move swiftly and deliver the controls to people at the right time. Their previous approach was to ship the Toolkit when every component was ready, and completely fleshed out.
Now they will be shipping the Toolkit with controls that might have different levels of quality (and they are clearly flagged in the documentation). Shawn explains the new "Quality Bands" model that they are using in his post.
You can try the components on the web. The charting control can be tried out with the ChartBuilder (check David's blog for details on the ChartBuilder):
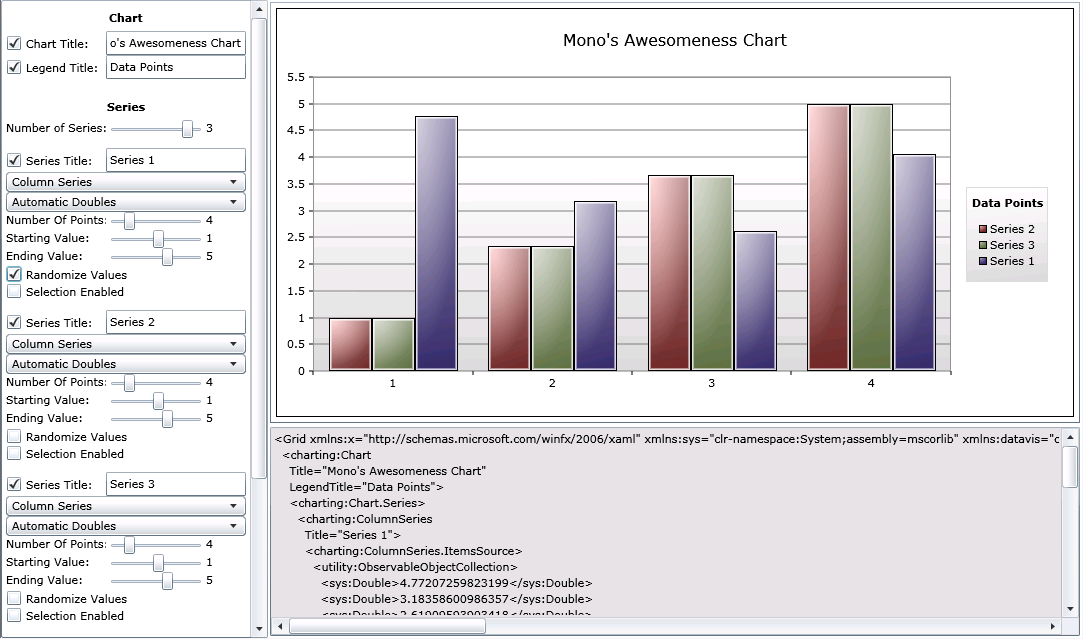
The source code for the Toolkit and the Controls is great to learn how to use Silverlight and it is great for people that need to tweak them for their own applications. When it comes to these controls, you no longer need Microsoft to make small changes for you or the small bug fixes that impact your application.
Themes: An interesting control container in Silverlight is the theming control. You wrap your code around this, and it will let you skin your control with XAML and define the animations and interactions with XAML and the Visual State Manager:

Some of these themes reminded me of the Gtk+ themes from 1998. Back in the days of Enlightenment and the "Cheese Pixmap" theme were hot. Mehdi explains how the themes work and Jafar explains the ImplicitStyleManager, the foundation for themes.
{kind=link}
Shawn's Talk
Shawn's talk at the PDC was very interesting. I did not get to see it during the conference, but I watched it in the comfort of home (wmv, mp4 and slide deck).
Posted on 10 Nov 2008
Moonlight Updates
 Last week we
branched Moonlight
for the 1.0 release, full with the licensed Microsoft Codecs
and started our release process for Moonlight Beta 1 to be
available in the next few days. This release is not yet
published on our web site, watch this space.
Last week we
branched Moonlight
for the 1.0 release, full with the licensed Microsoft Codecs
and started our release process for Moonlight Beta 1 to be
available in the next few days. This release is not yet
published on our web site, watch this space.
The Moonlight engine team has now resumed our work on Moonlight 2.0, the version that will track Silverlight 2.0.
In the meantime, while the GUI team was busy completing 1.0, the Mono core team has been working on the security framework for Moonlight, the networking stack (Silverlight allows Socket connections using policy files) and web services (System.ServiceModel, a subset of WCF).
The security system is the trickier and is the one that has received the most attention. We started early on last year in to implementing this, as we knew it would end up burning a lot of cycles to get it right.
Our hero has posted the initial work partition for the upcoming GUI work on Moonlight 2.0.
Moonlight is a blast, and who knows, maybe with our static compilation engine we might be able to deliver Silverlight on the iPhone.
Posted on 10 Nov 2008
Change.Gov
I wanted to thank everyone that helped get Barack Obama elected. Those that endorsed Obama passionately, those that videocasted, blogged, improved Obama's web site, donated to his campaign, wrote, discussed and voted on Tuesday to get him elected.
Barack does not only represent a change of direction for public policy, he is a truly brilliant candidate.
Some cool links on Barack:
- Larry Lessig: 20 minutes or so on why I am for Barack Obama.
- Tim O'Reilly's Why I Support Barack Obama.
- The Obama I know gives a glimpse of how Obama works.
- The Letter of Endorsement from 76 American Nobel Prize winners. winners.
- For the most cynics among us, you can watch the Chomsky on Obama interview which is as good as an endorsement as you can get from Noam.
- Beautiful pictures from the campaign trail from the Boston Globe.
I was surprised that the Obama campaign already launched their Change.Gov (thanks Nat) web site. You can now see how the team operates in real life, and you can share your story and you can share your vision of where America should go. The blog is here.
The above starts to deliver on the promise he had made during the campaign.
Got a cool collection of pictures about Obama or the reaction to the results? Please post it in the comments.
Inflamatory or misinformed comments will be deleted pronto.
Posted on 06 Nov 2008
Static Compilation in Mono
Another nice piece of technology that we showed at the PDC was static compilation, the feature behind allowing Mono to run on the iPhone in a fully legit way (no jail-breaking):

Screenshot from the Unity IDE.
Although Mono has supported batch compilation from CIL into native code in the past there was a small amount of code that was still generated dynamically. The intention originally was to help reduce startup and increase code sharing across multiple processes.
Code sharing is important once you have a handful of Mono processes running on the system. Instead of having to JIT the same code once per Mono instance for say "System.Console.WriteLine", the code laid out in essentially a shared object.
Our generated code uses many of the concepts found on the ELF file format to ensure that we can share code and that the code pages are read-only and not written to. This means that methods are invoked through a program linkage table instead of directly (to cope with the shared libraries being loaded at different addresses).
The Extra Mile
Although we are not certified XBox360 developers yet (we have yet to find the right person at Microsoft to talk to) we know from some of our users that have ported Mono to the XBox360 that JITing is not an option on that platform.
The XBox360 seems to have the same security-imposed limitations that the iPhone has, it is not possible for a Just-in-Time compiler to run in the platform as either the license terms or the kernel do not allow writable pages to become executable pages.
During the last few months we developed a static compilation mode for Mono. First we did this for the 1.0 profile, and now we are working on the 2.0 profile (so that we can support static compilation of generics). The work to support the 2.0 profile is reusing Mark's work on generic code sharing, which I found out to be a very nice synergy of efforts internally.
This means that it is now possible compile code from CIL to native code and not even ship the JIT compiler in your final program (saving some precious kilobytes from the final executable).
To do this, you must:
- Use Mono 2.0.1 at least.
- Request that Mono performs a full AOT compilation by using: mono --aot=full program.exe. That will generate your static executable. This executable still needs the runtime for things like garbage collection, threading and other runtime services.
- You then run your executable with Mono: mono --full-aot program.exe
- Optionally: build a new Mono on a separate location that removes the JIT engine by configuring Mono like this: configure --enable-minimal=jit. This will reduce your deployment by a few hundred Ks as the code generation and JIT engines are stripped out.
- Optionally: build a smaller set of libraries by using the Mono Linker (this is the tool that we use for turning Mono's 3.5 APIs into the Silverlight 2.0 APIs).
- Optionally: strip out the CIL code from the assemblies. We still require the assemblies for their rich metadata, but the actual CIL instructions can be safely removed. The new cil-strip tool built on top of Mono.Cecil can further shrink your deployed executables.
Developers interested in trimming down Mono can look into our documentation for more features that can be removed by using the --enable-minimal option.
Of course, once you remove the JIT you will not be able to use any dynamically generated code. This means no Reflection.Emit dynamically and at least for the time being or no IronPython/IronRuby.
John Lam told me at the PDC that they are looking into bringing static compilation for IronPython/IronRuby/DLR back, so this might just be a short-lived limitation.
For those interested in using Mono on the iPhone today the situation is a bit painful right now. You must run Mono on the target system to do the batch compilation and send the data back to assembly it on the host before you send the code back to the iPhone to run.
If you are wondering how did the demo go so smoothly at the PDC, the reason is that I was using Unity. Unity modified their local copy of Mono to be hardwired to do cross compilation to that exact platform. A more general purpose solution is needed to allow arbitrary platform-to-platform cross compilation, and we hope that this will be available in the future.
If you must quench your thirst for C# on the iPhone today your best choice is to use Unity's product and start building games instead of the enterprise application you always dreamed of.
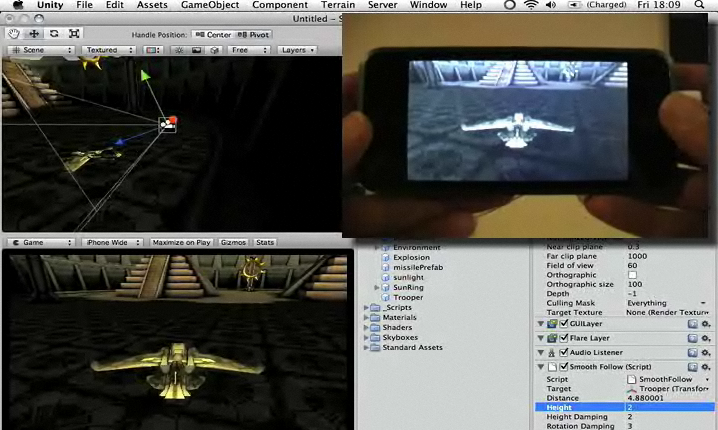
From the Unity's Video Sample
If your boss demands that line of application running on the iPhone, you have a perfect excuse to learn the Unity gaming APIs and deliver the most glorious multi-touch, 3D-transformed line of business application to ever grace this world full with spinning AI for your "Sort By Customer Last Name" button.
Posted on 05 Nov 2008
C# 4.0: var, object and dynamic
Anders presentation on C# 4 was as usual great to listen to. He continues to evolve the language with solid steps, and the presentation was quite fun.
You can watch his presentation or just read the slide deck.
With C# 4 the new "dynamic" keyword has been introduced to flag a variable as a dynamic variable.
This is slightly different than var and object, the differences are as follows:
- "object x" is a shorthand for "System.Object x". This declares the variable x to have the type System.Object, this is strongly typed. And since C# provides autoboxing, you can assign anything you want to this variable.
- "var x = E" declares a variable x to be of the type of the expression E. The E is required, not optional. This is a strongly typed declaration, and you can only assign values whose type is typeof(E) to it.
- "dynamic x" declares the variable x to have dynamic semantics. This means that the C# compiler will generate code that will allow dynamic invocations on x. The actual meaning of "x.M" is deferred until runtime and will depend on the semantics of the IDynamicObject implementation.
Posted on 03 Nov 2008
Mono's SIMD Support: Making Mono safe for Gaming
This week at the Microsoft PDC we introduced a new feature in the Mono virtual machine that we have been working on quietly and will appear in our upcoming Mono 2.2 release (due in early December).
I believe we are the first VM for managed code that provides an object-oriented API to the underlying CPU SIMD instructions.
In short, this means that developers will be able to use the types in the Mono.Simd library and have those mapped directly to efficient vector operations on the hardware that supports it.
With Mono.Simd, the core of a vector operations like updating the coordinates on an existing vector like the following example will go from 40-60 CPU instructions into 4 or so SSE instructions.
Vector4f Move (Vector4f [] pos, ref Vector4f delta)
{
for (int i = 0; i < pos.Length; i++)
pos [i] += delta;
}
Which in C# turns out to be a call into the method Vector4f.operator + (Vector4f a, Vector4f b) that is implemented like this:
Vector4f static operator + (Vector3f a, Vector3f b)
{
return new Vector4f (a.x+b.x, a.y+b.y, a.z+b.z, a.w+b.w);
}
The core of the operation is inlined in the `Move' method and it looks like this:
movups (%eax),%xmm0 movups (%edi),%xmm1 addps %xmm1,%xmm0 movups %xmm0,(%eax)
You can see the details on the slides that I used at the PDC and look at the changes in the generated assembly, they are very large.
Ideally, once we tune the API based on our user feedback and contributions, it should be brought to ECMA for standardization. Hopefully we can get Microsoft to implement the SIMD support as well so all .NET developers have access to this.
Making Managed Code Viable for Gaming
Many developers have to resort to C++ or assembly language because managed languages did not provide the performance they needed. We believe that we can bring the productivity gains of managed languages to developers that seek high performance applications:
But even if you want to keep using your hand-tuned C++ game engine, the SIMD extensions will improve the performance of your scripting code. You can accelerate your ray casting operations by doing all the work in the managed world instead of paying for a costly managed to unmanaged transition and back.
You can avoid moving plenty of code from C# into C++ with this new functionality.
Some SIMD Background
Most modern CPUs contain special instructions that are able to perform arithmetic operations on multiple values at once. For example it is possible to add two 4-float vectors in one pass, or perform these arithmetic operations on 16-bytes at a time.
These are usually referred to as SIMD instructions and started showing up a few years ago in CPUs. On x86-class machines these new instructions were part of MMX, 3DNow or the SSEx extensions, on PowerPC these are called Altivec.
CPU manufacturers have been evolving the extensions, and newer versions always include more functionality and expand on the previous generations.
On x86 processors these instructions use a new register bank (the XMM registers) and can be configured to work on 16 bytes at a time using a number of possible combinations:
- byte-level operations on 16 elements.
- short-level operations on 8 elements.
- single precision or integer-level operations on 4 elements.
- double precision or long-integer operations on 2 elements.
The byte level operations are useful for example when doing image composition, scaling or format conversions. The floating point operations are useful for 3D math or physics simulations (useful for example when building video games).
Typically developers write the code in assembly language to take advantage of this feature, or they use compiler-specific intrinsic operations that map to these underlying instructions.
The Idea
Unlike native code generated by a compiler, Common Intermediate Language (CIL) or Java class files contain enough semantic information from the original language that it is very easy to build tools to compute code metrics (with tools like NDepend), find bugs in the code (with tools like Gendarme or FxCop, recreate the original program flow-analysis with libraries like Cecil.FlowAnalysis or even decompile the code and get back something relatively close to the original source code.
With this rich information, virtual machines can tune code when it is just-in-time compiled on a target system by tuning the code to best run on a particular system or recompiling the code on demand.
We had proposed in the past mechanisms to improve code performance of specific code patterns or languages like Lisp by creating special helper classes that are intimately linked with the runtime.
As Mono continues to be used as a high-performance scripting engine for games we were wondering how we could better serve our gaming users.
During the Game Developer Conference early this year, we had a chance to meet with Realtime Worlds which is using the Mono as their foundation for their new work and we wanted to understand how we could help them be more effective.
One of the issues that came up was the performance of Vector operations and how this could be optimized. We discussed with them the possibility of providing an object-oriented API that would map directly to the SIMD hardware available on modern computers. Realtime Worlds shared with us their needs in this space, and we promised that we would look into this.
The Development
Our initial discussion with Realtime Worlds was in May, and at the time we were working both towards Mono 2.0 and also on a new code generation engine that would improve Mono's performance.
The JIT engine that shipped with Mono 2.0 was not a great place to start adding SIMD support, so we decided to postpone this work until we switched Mono to the Linear IL engine.
Rodrigo started work on a proof-of-concept implementation for SIMD and after a weekend he managed to get the basics in place and got a simple demo working.
Beyond the proof of concept, there was a lingering question: were the benefits of Vector operations going to be noticeably faster than the regular code? We were afraid that the register spill/reload would eclipse the benefits of using the SIMD instructions or that our assumptions had been wrong.
Over the next few weeks the rest of the team worked with Rodrigo to turn the prototype into something that could be both integrated into Mono and would execute efficiently (Zoltan, Paolo and Mark).
For example, with Mono 2.2 we will now align the stack conveniently to a 16-byte boundary to improve performance for stack-allocated Mono.SIMD structures.
So far the reception from developers building games has been very positive.
Although today we only support x86 up to SSE3 and some SSE4, we will be expanding both the API and the reach of of our SIMD mapping based on our users feedback. For example, on other architectures we will map the operations to their own SIMD instructions.
The API
The API lives in the Mono.Simd assembly and is available today from our SVN Repository (browse the API or get a tarball). You can also check our Mono.Simd documentation.
This assembly can be used in Mono or .NET and contains the following hardware accelerated types (as of today):
Mono.Simd.Vector16b - 16 unsigned bytes Mono.Simd.Vector16sb - 16 signed bytes Mono.Simd.Vector2d - 2 doubles Mono.Simd.Vector2l - 2 signed 64-bit longs Mono.Simd.Vector2ul - 2 unsigned 64-bit longs Mono.Simd.Vector4f - 4 floats Mono.Simd.Vector4i - 4 signed 32-bit ints Mono.Simd.Vector4ui - 4 unsigned 32-bit ints Mono.Simd.Vector8s - 8 signed 16-bit shorts Mono.Simd.Vector8us - 8 unsigned 16-bit shorts
The above are structs that occupy 16 bytes each, very similar to equivalent types found on libraries like OpenTK.
Our library provides C# fallbacks for all of the accelerated instructions. This means that if your code runs on a machine that does not provide any SIMD support, or one of the operations that you are using is not supported in your machine, the code will continue to work correctly.
This also means that you can use the Mono.Simd API with Microsoft's .NET on Windows to prototype and develop your code, and then run it at full speed using Mono.
With every new generation of SIMD instructions, new features are supported. To provide a seamless experience, you can always use the same API and Mono will automatically fallback to software implementations if the target processor does not support the instructions.
For the sake of documentation and to allow developers to detect at runtime if a particular method is hardware accelerated developers can use the Mono.Simd.SimdRuntime.IsMethodAccelerated method or look at the [Acceleration] atribute on the methods to identify if a specific method is hardware accelerated.
The Speed Tests
When we were measuring the performance improvement of the SIMD extensions we wrote our own home-grown tests and they showed some nice improvements. But I wanted to implement a real game workload and compare it to the non-accelerated case.
I picked a C++ implementation and did a straight-forward port to Mono.Simd without optimizing anything to compare Simd vs Simd. The result was surprising, as it was even faster than the C++ version:
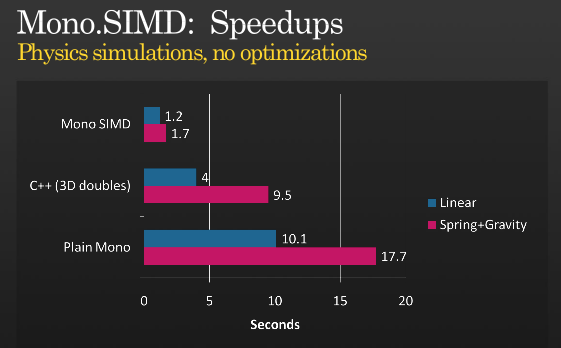
Based on the C++ code from F# for Game Development
The source code for the above tests is available here.
I use the C++ version just because it peeked my curiosity. If you use compiler-specific features in C++ to use SIMD instructions you will likely improve the C++ performance (please post the updated version and numbers if you do).
I would love to see whether Johann Deneux from the F# for Game Development Blog could evaluate the performance of Mono.Simd in his scenarios.
If you are curious and want to look at the assembly code generated with or without the SIMD optimizations, you want to call Mono's runtime with the -v -v flags (yes, twice) and use -O=simd and -O=-simd to enable or disable it.
Presentation
You can watch the presentation to get some color into the above discussion or check it in the Silverlight player, Get it as PDF, or PPTX.
Posted on 03 Nov 2008
Interactive GUI Shell
This week at the Microsoft PDC I showed gsharp, our GUI repl for the C# 3.0 language, a tool that I had previously talked about.
Before the PDC we copied an idea from Owen's great reinteract shell where we provide our REPL with a mechanism to turn objects into Gtk.Widgets which we then insert.
Out of the box we support System.Drawing.Bitmap images, we turn those into Gtk Widgets that then we render:
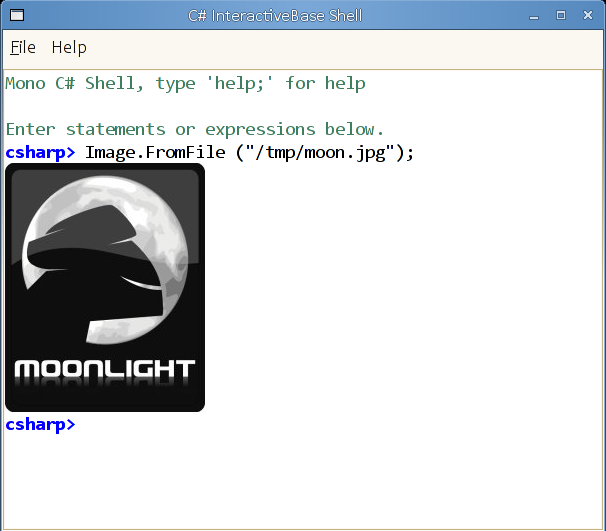
I also added a toy Plot command that can take a number of lambdas that return floats to do some cute plots. The plots are just rendered into a System.Drawing.Bitmap so they get painted on the screen automatically:
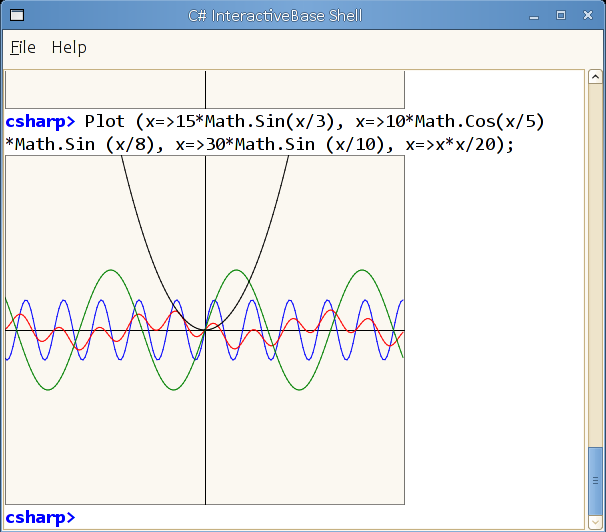
But you can add your own handlers for any data types you want, all you have to do is call RegisterTransformHandler with a function that can return a Gtk.Widget based on an input object, or null if it does not know how to render it.
The implementation to render images is very simple, this is the implementation:
using System;
public class MyRenderHelpers {
public static object RenderBitmaps (object o)
{
System.Drawing.Bitmap bitmap = o as System.Drawing.Bitmap;
if (bitmap == null)
return null;
return new BitmapWidget (bitmap);
}
}
You can put your own library of helper methods in a compiled assembly in ~/.config/gsharp, and then register all of your types from a file ending with the extension .cs in ~/.config/gsharp:
RegisterTransformHandler (MyRenderHelpers.RenderBitmaps);
And you are done.
The above could be used for example to create all kinds of information visualizers for the GUI REPL. I would love to see a LINQ query navigator, similar to the one in LinqPad.
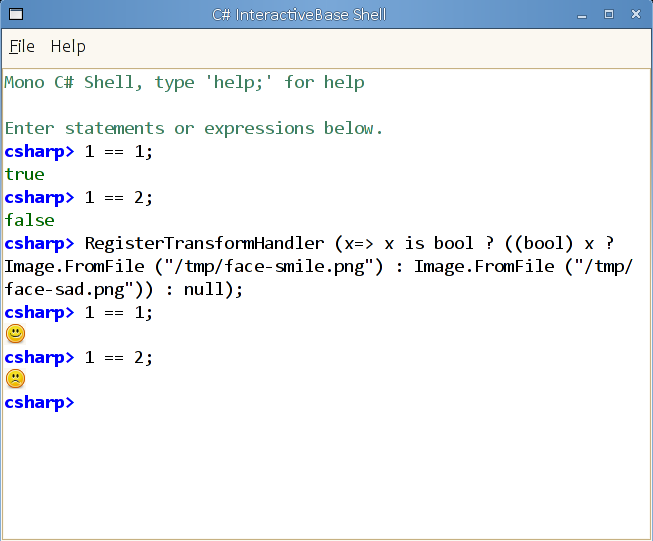
Update: A one line change that brings gsharp into the new millenium by rendering `true' and `false' with icons instead of text:
Posted on 02 Nov 2008
Mono and .NET talk at PDC video.
The PDC 2008 was a blast. It was a privilege to be able to present Mono to all of these developers.
Joseph Hill helped me prepare my presentation for the PDC. Our goal was to explore how Mono could help .NET developers, but we did not want to go down a laundry list of features, or a list of APIs, or rehash what the advanced audience at the PDC already knew.

The idea was to pick a couple of interesting innovations from Mono and try stitch a story together. I discussed our embeddable C# compiler (which we need to start calling "Compiler Service"), some applications of Mono in gaming, our recent SIMD extensions and using Mono on the iPhone.
As for me, I am catching up on all the sessions I missed this weekend. All of the videos and slide decks are available for free from the Microsoft PDC site, and republished in Channel9.
In the next few days I will blog in more detail about each topic.
Posted on 02 Nov 2008
Blog Search
Archive
- 2024
Apr - 2020
Mar Aug Sep - 2018
Jan Feb Apr May Dec - 2016
Jan Feb Jul Sep - 2014
Jan Apr May Jul Aug Sep Oct Nov Dec - 2012
Feb Mar Apr Aug Sep Oct Nov - 2010
Jan Feb Mar Apr May Jun Jul Aug Sep Oct Nov Dec - 2008
Jan Feb Mar Apr May Jun Jul Aug Sep Oct Nov Dec - 2006
Jan Feb Mar Apr May Jun Jul Aug Sep Oct Nov Dec - 2004
Jan Feb Mar Apr May Jun Jul Aug Sep Oct Nov Dec - 2002
Jan Feb Mar Apr May Jun Jul Aug Sep Oct Dec
- 2022
Apr - 2019
Mar Apr - 2017
Jan Nov Dec - 2015
Jan Jul Aug Sep Oct Dec - 2013
Feb Mar Apr Jun Aug Oct - 2011
Jan Feb Mar Apr May Jun Jul Aug Sep Oct Nov Dec - 2009
Jan Feb Mar Apr May Jun Jul Aug Sep Oct Nov Dec - 2007
Jan Feb Mar Apr May Jun Jul Aug Sep Oct Nov Dec - 2005
Jan Feb Mar Apr May Jun Jul Aug Sep Oct Nov Dec - 2003
Jan Feb Mar Apr Jun Jul Aug Sep Oct Nov Dec - 2001
Apr May Jun Jul Aug Sep Oct Nov Dec