XNA on Windows 8 Metro
The MonoGame
Team has been working on adding Windows 8 Metro support to
MonoGame.
This will be of interest to all XNA developers that wanted to target the Metro AppStore, since Microsoft does not plan on supporting XNA on Metro, only on the regular desktop.
The effort is taking place on IRC in the #monogame channel on irc.gnome.org. The code is being worked in the develop3d branch of MonoGame.
Posted on 19 Apr 2012
Contributing to Mono 4.5 Support
For a couple of weeks I have been holding off on posting about how to contribute to Mono, since I did not have a good place to point people to.
Gonzalo has just updated our Status pages to include the differences betwee .NET 4.0 to .NET 4.5, these provide a useful roadmap for features that should be added to Mono.
This in particular in the context of ASP.NET 4.5, please join us in [email protected].
Posted on 13 Apr 2012
Modest Proposal for C#
This is a trivial change to implement, and would turn what today is an error into useful behavior.
Consider the following C# program:
struct Rect {
public int X, Y, Width, Height;
}
class Window {
Rect bounds;
public Rect Bounds {
get { return bounds; }
set {
// Some code that needs to run when the property is set
WindowManager.Invalidate (bounds);
WindowManager.Invalidate (value);
bounds = value;
}
}
}
Currently, code like this:
Window w = new Window (); w.Bounds.X = 10;
Produces the error:
Cannot modify the return value of "Window.Bounds.X" because it is not a variable
The reason is that the compiler returns a copy of the "bounds" structure and making changes to the returned value has no effect on the original property.
If we had used a public field for Bounds, instead of a property, the above code would compile, as the compiler knows how to get to the "Bounds.X" field and set its value.
My suggestion is to alter the C# compiler to turn what today is considered an error when accessing properties and doing what the developer expects.
The compiler would rewrite the above code into:
Window w = new Window (); var tmp = w.Bounds; tmp.X = 10; w.Bounds = tmp;
Additionally, it should cluster all of the changes done in a single call, so:
Window w = new Window (); w.Bounds.X = 10; w.Bounds.Y = 20;
Will be compiled as:
Window w = new Window (); var tmp = w.Bounds; tmp.X = 10; tmp.Y = 20; w.Bounds = tmp;
To avoid calling the setter for each property set in the underlying structure.
The change is trivial and wont break any existing code.
Posted on 11 Apr 2012
Can JITs be faster?
Herb Sutter discusses in his Reader QA: When Will Better JITs save Managed Code?:
In the meantime, short answer: C++ and managed languages make different fundamental tradeoffs that opt for either performance or productivity when they are in tension.[...]
This is a 199x/200x meme that’s hard to kill – “just wait for the next generation of (JIT or static) compilers and then managed languages will be as efficient.” Yes, I fully expect C# and Java compilers to keep improving – both JIT and NGEN-like static compilers. But no, they won’t erase the efficiency difference with native code, for two reasons.
First, JIT compilation isn’t the main issue. The root cause is much more fundamental: Managed languages made deliberate design tradeoffs to optimize for programmer productivity even when that was fundamentally in tension with, and at the expense of, performance efficiency. (This is the opposite of C++, which has added a lot of productivity-oriented features like auto and lambdas in the latest standard, but never at the expense of performance efficiency.) In particular, managed languages chose to incur costs even for programs that don’t need or use a given feature; the major examples are assumption/reliance on always-on or default-on garbage collection, a virtual machine runtime, and metadata.
This is a pretty accurate statement on the difference of the mainstream VMs for managed languages (.NET, Java and Javascript).
Designers of managed languages have chosen the path of safety over performance for their designs. For example, accessing elements outside the boundaries of an array is an invalid operation that terminates program execution, as opposed to crashing or creating an exploitable security hole.
But I have an issue with these statements:
Second, even if JIT were the only big issue, a JIT can never be as good as a regular optimizing compiler because a JIT compiler is in the business of being fast, not in the business of generating optimal code. Yes, JITters can target the user’s actual hardware and theoretically take advantage of a specific instruction set and such, but at best that’s a theoretical advantage of NGEN approaches (specifically, installation-time compilation), not JIT, because a JIT has no time to take much advantage of that knowledge, or do much of anything besides translation and code gen.
In general the statement is correct when it comes to early Just-in-Time compilers and perhaps reflects Microsoft's .NET JIT compiler, but this does not apply to state of the art JIT compilers.
Compilers are tools that convert human readable text into machine code. The simplest ones perform straight forward translations from the human readable text into machine code, and typically go through or more of these phases:

Optimizing compilers introduce a series of steps that alter their inputs to ensure that the semantics described by the user are preserved while generating better code:
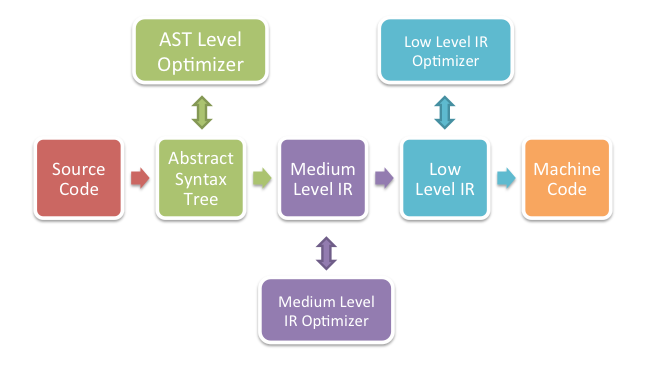
An optimization that could be performed on the high-level representation would transform the textual "5 * 4" in the source code into the constant 20. This is an easy optimization that can be done up-front. Simple dead code elimination based on constant folding like "if (1 == 2) { ... }" can also be trivially done at this level.
An optimization on the medium representation would analyze the use of variables and could merge subexpressions that are computed more than once, for example:
int j = (a*b) + (a*b)
Would be transformed by the compiler into:
int _tmp = a * b; int j = _tmp + _tmp;
A low-level optimization would alter a "MULTIPLY REGISTER-1 BY 2" instruction into "SHIFT REGISTER-1 ONE BIT TO THE LEFT".
JIT compilers for Java and .NET essentially break the
compilation process in two. They serialize the data in the
compiler pipeline and split the process in two. The first
part of the process dumps the result into a .dll
or .class files:
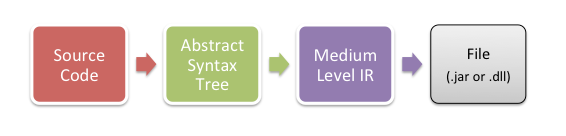
The second step loads this file and generates the native code. This is similar to purchasing frozen foods from the super market, you unwrap the pie, shove it in the oven and wait 15 minutes:

Saving the intermediate representation and shipping it off to a new system is not a new idea. The TenDRA C and C++ compilers did this. These compilers saved their intermediate representation into an architecture neutral format called ANDF, similar in spirit to .NET's Common Intermediate Language and Java's bytecode. TenDRA used to have an installer program which was essentially a compiler for the target architecture that turned ANDF into native code.
Essentially JIT compilers have the same information than a batch compiler has today. For a JIT compiler, the problem comes down to striking a balance between the quality of the generated code and the time it takes to generate the code.
JIT compilers tend to go for fast compile times over quality of the generated code. Mono allows users to configure this threshold by allowing users to pick the optimization level defaults and even lets them pick LLVM to perform the heavy duty optimizations on the code. Slow, but the generated code quality is the same code quality you get from LLVM with C.
Java HotSpot takes a fascinating approach: they do a quick compilation on the first pass, but if the VM detects that a piece of code is being used a lot, the VM recompiles the code with all the optimization turned on and then they hot-swap the code.
.NET has a precompiler called NGen, and Mono allows the --aot flag to be passed to perform the equivalent process that TenDRA's installer did. They precompile the code tuned for the current hardware architecture to avoid having the JIT compiler spend time at runtime translating .NET CIL code to native code.
In Mono's case, you can use the LLVM optimizing compiler as the backend for precompiling code, which produces great code. This is the same compiler that Apple now uses on Lion and as LLVM improves, Mono's generated code improves.
NGen has a few limitations in the quality of the code that it can produce. Unlike Mono, NGen acts merely as a pre-compiler and tests suggest that there are very limited extra optimizations applied. I believe NGen's limitations are caused by .NET's Code Access Security feature which Mono never implemented [1].
[1] Mono only supports the CoreCLR security system, but that is an opt-in feature that is not enabled for desktop/server/mobile use. A special set of assemblies are shipped to support this.
Optimizing JIT compilation for Managed Languages
Java, JavaScript and .NET have chosen a path of productivity and safety over raw performance.
This means that they provide automatic memory management, arrays bounds checking and resource tracking. Those are really the elements that affect the raw performance of these languages.
There are several areas in which managed runtimes can evolve to improve their performance. They wont ever match the performance of hand-written assembly language code, but here are some areas that managed runtimes can work on to improve performance:
>Alias analysis is simpler as arrays are accessed with array operations instead of pointer arithmetic.
Intent: with the introduction of LINQ in C#, developers can shift their attention from how a particular task is done to expressing the desired outcome of an operation. For example:
var biggerThan10 = new List; for (int i = 0; i < array.Length; i++){ if (array [i] > 10) biggerThan10.Add (i); }
Can be expressed now as:
var biggerThan10 = x.Where (x => x > 10).Select (x=>x); // with LINQ syntax: var biggerThan10 = from x in array where x > 10 select x;
Both managed compilers and JIT compilers can take advantage of the rich information that is preserved to turn the expressed intent into an optimized version of the code.
Extend VMs: Just like Javascript was recently extended to support strongly typed arrays to improve performance, both .NET and Java can be extended to allow fewer features to be supported at the expense of safety.
.NET could allow developers to run without the CAS sandbox and without AppDomains (like Mono does).
Both .NET and Java could offer "unsafe" sections that would allow performance critical code to not enforce arrays-bounds-optimization (at the expense of crashing or creating a security gap, this can be done today in Mono by using -O=unsafe).
.NET and Mono could provide allocation primitives that allocate objects on a particular heap or memory pool:
var pool = MemoryPool.Allocate (1024*1024); // Allocate the TerrainMesh in the specified memory pool var p = new pool, TerrainMesh (); [...] // Release all objects from the pool, all references are // nulled out // Assert.NotEquals (p, null); pool.Destroy (); Assert.Equals (p, null);
Limiting Dynamic Features: Current JIT compilers for Java and .NET have to deal with the fact that code can be extended dynamically by either loading code at runtime or generating code dynamically.
HotSpot leverages its code recompiled to implement sophisticated techniques to perform devirtualization safely.
On iOS and other platforms it is not possible to generate code dynamically, so code generators could trivially devirtualize, inline certain operations and drop features from both their runtimes and the generated code.
More Intrinsics: An easy optimization that JIT engines can do is map common constructs into native features. For example, we recently inlined the use of ThreadLocal<T> variables. Many Math.* methods can be inlined, and we applied this technique to Mono.SIMD.
Posted on 04 Apr 2012
Blog Search
Archive
- 2024
Apr Jun - 2020
Mar Aug Sep - 2018
Jan Feb Apr May Dec - 2016
Jan Feb Jul Sep - 2014
Jan Apr May Jul Aug Sep Oct Nov Dec - 2012
Feb Mar Apr Aug Sep Oct Nov - 2010
Jan Feb Mar Apr May Jun Jul Aug Sep Oct Nov Dec - 2008
Jan Feb Mar Apr May Jun Jul Aug Sep Oct Nov Dec - 2006
Jan Feb Mar Apr May Jun Jul Aug Sep Oct Nov Dec - 2004
Jan Feb Mar Apr May Jun Jul Aug Sep Oct Nov Dec - 2002
Jan Feb Mar Apr May Jun Jul Aug Sep Oct Dec
- 2022
Apr - 2019
Mar Apr - 2017
Jan Nov Dec - 2015
Jan Jul Aug Sep Oct Dec - 2013
Feb Mar Apr Jun Aug Oct - 2011
Jan Feb Mar Apr May Jun Jul Aug Sep Oct Nov Dec - 2009
Jan Feb Mar Apr May Jun Jul Aug Sep Oct Nov Dec - 2007
Jan Feb Mar Apr May Jun Jul Aug Sep Oct Nov Dec - 2005
Jan Feb Mar Apr May Jun Jul Aug Sep Oct Nov Dec - 2003
Jan Feb Mar Apr Jun Jul Aug Sep Oct Nov Dec - 2001
Apr May Jun Jul Aug Sep Oct Nov Dec