Mono's SIMD Support: Making Mono safe for Gaming
This week at the Microsoft PDC we introduced a new feature in the Mono virtual machine that we have been working on quietly and will appear in our upcoming Mono 2.2 release (due in early December).
I believe we are the first VM for managed code that provides an object-oriented API to the underlying CPU SIMD instructions.
In short, this means that developers will be able to use the types in the Mono.Simd library and have those mapped directly to efficient vector operations on the hardware that supports it.
With Mono.Simd, the core of a vector operations like updating the coordinates on an existing vector like the following example will go from 40-60 CPU instructions into 4 or so SSE instructions.
Vector4f Move (Vector4f [] pos, ref Vector4f delta)
{
for (int i = 0; i < pos.Length; i++)
pos [i] += delta;
}
Which in C# turns out to be a call into the method Vector4f.operator + (Vector4f a, Vector4f b) that is implemented like this:
Vector4f static operator + (Vector3f a, Vector3f b)
{
return new Vector4f (a.x+b.x, a.y+b.y, a.z+b.z, a.w+b.w);
}
The core of the operation is inlined in the `Move' method and it looks like this:
movups (%eax),%xmm0 movups (%edi),%xmm1 addps %xmm1,%xmm0 movups %xmm0,(%eax)
You can see the details on the slides that I used at the PDC and look at the changes in the generated assembly, they are very large.
Ideally, once we tune the API based on our user feedback and contributions, it should be brought to ECMA for standardization. Hopefully we can get Microsoft to implement the SIMD support as well so all .NET developers have access to this.
Making Managed Code Viable for Gaming
Many developers have to resort to C++ or assembly language because managed languages did not provide the performance they needed. We believe that we can bring the productivity gains of managed languages to developers that seek high performance applications:
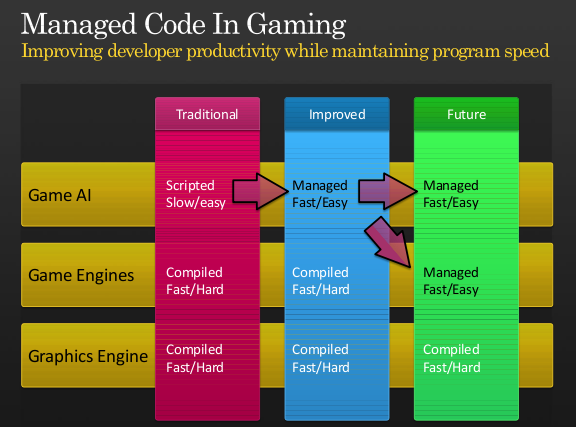
But even if you want to keep using your hand-tuned C++ game engine, the SIMD extensions will improve the performance of your scripting code. You can accelerate your ray casting operations by doing all the work in the managed world instead of paying for a costly managed to unmanaged transition and back.
You can avoid moving plenty of code from C# into C++ with this new functionality.
Some SIMD Background
Most modern CPUs contain special instructions that are able to perform arithmetic operations on multiple values at once. For example it is possible to add two 4-float vectors in one pass, or perform these arithmetic operations on 16-bytes at a time.
These are usually referred to as SIMD instructions and started showing up a few years ago in CPUs. On x86-class machines these new instructions were part of MMX, 3DNow or the SSEx extensions, on PowerPC these are called Altivec.
CPU manufacturers have been evolving the extensions, and newer versions always include more functionality and expand on the previous generations.
On x86 processors these instructions use a new register bank (the XMM registers) and can be configured to work on 16 bytes at a time using a number of possible combinations:
- byte-level operations on 16 elements.
- short-level operations on 8 elements.
- single precision or integer-level operations on 4 elements.
- double precision or long-integer operations on 2 elements.
The byte level operations are useful for example when doing image composition, scaling or format conversions. The floating point operations are useful for 3D math or physics simulations (useful for example when building video games).
Typically developers write the code in assembly language to take advantage of this feature, or they use compiler-specific intrinsic operations that map to these underlying instructions.
The Idea
Unlike native code generated by a compiler, Common Intermediate Language (CIL) or Java class files contain enough semantic information from the original language that it is very easy to build tools to compute code metrics (with tools like NDepend), find bugs in the code (with tools like Gendarme or FxCop, recreate the original program flow-analysis with libraries like Cecil.FlowAnalysis or even decompile the code and get back something relatively close to the original source code.
With this rich information, virtual machines can tune code when it is just-in-time compiled on a target system by tuning the code to best run on a particular system or recompiling the code on demand.
We had proposed in the past mechanisms to improve code performance of specific code patterns or languages like Lisp by creating special helper classes that are intimately linked with the runtime.
As Mono continues to be used as a high-performance scripting engine for games we were wondering how we could better serve our gaming users.
During the Game Developer Conference early this year, we had a chance to meet with Realtime Worlds which is using the Mono as their foundation for their new work and we wanted to understand how we could help them be more effective.
One of the issues that came up was the performance of Vector operations and how this could be optimized. We discussed with them the possibility of providing an object-oriented API that would map directly to the SIMD hardware available on modern computers. Realtime Worlds shared with us their needs in this space, and we promised that we would look into this.
The Development
Our initial discussion with Realtime Worlds was in May, and at the time we were working both towards Mono 2.0 and also on a new code generation engine that would improve Mono's performance.
The JIT engine that shipped with Mono 2.0 was not a great place to start adding SIMD support, so we decided to postpone this work until we switched Mono to the Linear IL engine.
Rodrigo started work on a proof-of-concept implementation for SIMD and after a weekend he managed to get the basics in place and got a simple demo working.
Beyond the proof of concept, there was a lingering question: were the benefits of Vector operations going to be noticeably faster than the regular code? We were afraid that the register spill/reload would eclipse the benefits of using the SIMD instructions or that our assumptions had been wrong.
Over the next few weeks the rest of the team worked with Rodrigo to turn the prototype into something that could be both integrated into Mono and would execute efficiently (Zoltan, Paolo and Mark).
For example, with Mono 2.2 we will now align the stack conveniently to a 16-byte boundary to improve performance for stack-allocated Mono.SIMD structures.
So far the reception from developers building games has been very positive.
Although today we only support x86 up to SSE3 and some SSE4, we will be expanding both the API and the reach of of our SIMD mapping based on our users feedback. For example, on other architectures we will map the operations to their own SIMD instructions.
The API
The API lives in the Mono.Simd assembly and is available today from our SVN Repository (browse the API or get a tarball). You can also check our Mono.Simd documentation.
This assembly can be used in Mono or .NET and contains the following hardware accelerated types (as of today):
Mono.Simd.Vector16b - 16 unsigned bytes Mono.Simd.Vector16sb - 16 signed bytes Mono.Simd.Vector2d - 2 doubles Mono.Simd.Vector2l - 2 signed 64-bit longs Mono.Simd.Vector2ul - 2 unsigned 64-bit longs Mono.Simd.Vector4f - 4 floats Mono.Simd.Vector4i - 4 signed 32-bit ints Mono.Simd.Vector4ui - 4 unsigned 32-bit ints Mono.Simd.Vector8s - 8 signed 16-bit shorts Mono.Simd.Vector8us - 8 unsigned 16-bit shorts
The above are structs that occupy 16 bytes each, very similar to equivalent types found on libraries like OpenTK.
Our library provides C# fallbacks for all of the accelerated instructions. This means that if your code runs on a machine that does not provide any SIMD support, or one of the operations that you are using is not supported in your machine, the code will continue to work correctly.
This also means that you can use the Mono.Simd API with Microsoft's .NET on Windows to prototype and develop your code, and then run it at full speed using Mono.
With every new generation of SIMD instructions, new features are supported. To provide a seamless experience, you can always use the same API and Mono will automatically fallback to software implementations if the target processor does not support the instructions.
For the sake of documentation and to allow developers to detect at runtime if a particular method is hardware accelerated developers can use the Mono.Simd.SimdRuntime.IsMethodAccelerated method or look at the [Acceleration] atribute on the methods to identify if a specific method is hardware accelerated.
The Speed Tests
When we were measuring the performance improvement of the SIMD extensions we wrote our own home-grown tests and they showed some nice improvements. But I wanted to implement a real game workload and compare it to the non-accelerated case.
I picked a C++ implementation and did a straight-forward port to Mono.Simd without optimizing anything to compare Simd vs Simd. The result was surprising, as it was even faster than the C++ version:
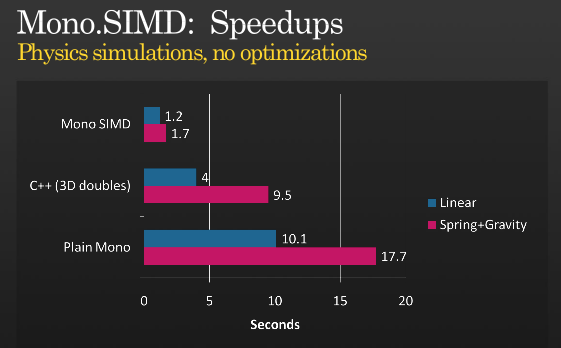
Based on the C++ code from F# for Game Development
The source code for the above tests is available here.
I use the C++ version just because it peeked my curiosity. If you use compiler-specific features in C++ to use SIMD instructions you will likely improve the C++ performance (please post the updated version and numbers if you do).
I would love to see whether Johann Deneux from the F# for Game Development Blog could evaluate the performance of Mono.Simd in his scenarios.
If you are curious and want to look at the assembly code generated with or without the SIMD optimizations, you want to call Mono's runtime with the -v -v flags (yes, twice) and use -O=simd and -O=-simd to enable or disable it.
Presentation
You can watch the presentation to get some color into the above discussion or check it in the Silverlight player, Get it as PDF, or PPTX.
Posted on 03 Nov 2008
Blog Search
Archive
- 2024
Apr Jun - 2020
Mar Aug Sep - 2018
Jan Feb Apr May Dec - 2016
Jan Feb Jul Sep - 2014
Jan Apr May Jul Aug Sep Oct Nov Dec - 2012
Feb Mar Apr Aug Sep Oct Nov - 2010
Jan Feb Mar Apr May Jun Jul Aug Sep Oct Nov Dec - 2008
Jan Feb Mar Apr May Jun Jul Aug Sep Oct Nov Dec - 2006
Jan Feb Mar Apr May Jun Jul Aug Sep Oct Nov Dec - 2004
Jan Feb Mar Apr May Jun Jul Aug Sep Oct Nov Dec - 2002
Jan Feb Mar Apr May Jun Jul Aug Sep Oct Dec
- 2022
Apr - 2019
Mar Apr - 2017
Jan Nov Dec - 2015
Jan Jul Aug Sep Oct Dec - 2013
Feb Mar Apr Jun Aug Oct - 2011
Jan Feb Mar Apr May Jun Jul Aug Sep Oct Nov Dec - 2009
Jan Feb Mar Apr May Jun Jul Aug Sep Oct Nov Dec - 2007
Jan Feb Mar Apr May Jun Jul Aug Sep Oct Nov Dec - 2005
Jan Feb Mar Apr May Jun Jul Aug Sep Oct Nov Dec - 2003
Jan Feb Mar Apr Jun Jul Aug Sep Oct Nov Dec - 2001
Apr May Jun Jul Aug Sep Oct Nov Dec