A Cool Mono Success Story
Salvatore Scarciglia wrote an email today to tell me their story of using Mono on Clinical Trials. His team currently uses Oracle Clinical Trials, but when they wanted new features, they decided that it was better for them to build their own software than licensing the extra modules they needed to grow.
Salvatore has a description of their project where he explains why they built the software using .NET in the first place (they were mostly a Microsoft shop, with Microsoft servers, and they liked Visual Studio).
Recently something changed:
I believe in Mono (take a look at the projects page of this site) and I think that it can grows very fast in the next years. When I read that one of the latest release of Mono supports almost all the .NET Framework 2.0 I've decided to try our framework with it. The original architecture based on:Windows Server 2003 + .NET Framework 2.0 + SQL Server 2005 has been substitute with:
Debian 4 + Apache + Mono 1.2.5 (mod_mono2) + MySQL (with .NET connector) and... it works !
It was very hard to rewrite all the stored procedures and views developed with T-SQL in SQL Server, but at the end all the "dirty" work was done. On the other hand Monodevelop 0.16 has compiled the entire framework with no errors. The .NET connector provided by the MySQL team works fine and, finally, Apache + mod_mono was not so easy to configure but I did it.
Using Microsoft technology you have the advantage to use the best development environment (Visual Studio 2005), a fully supported database engine (SQL Server 2005) and the availability of many documentation and tutorial sites (first of all the MSDN). Using Mono you have the great opportunity to develop in C# on Linux.
[Ed: some typos fixed by my speller while quoting.]
This has also been our experience: porting the stored procedures from a SQL server to another is probably the most time consuming piece of work and it is also not mandatory. Mono comes with a SQL Server provider, and if you just want to replace your front-end ASP.NET servers with Linux hosts, you can continue to talk to your backend MS SQL Server if you want to.
Sadly, it has also been our experience that the most difficult piece to setup in Mono is mod_mono. The last time I set it up it was difficult, and people regularly have problems setting it up. A year or so ago, we came up with a pretty cool extension to mod_mono that (in my mind) simplified the deployment: AutoHosting, but it does not seem to be enough.
Am hoping that the new the FastCGI support for Mono will make it simpler to configure for some setups.
If you are interested in porting your ASP.NET application to Linux, you will like Marek Habersack's tutorial on porting ASP.NET apps that covers many of the details.
Posted on 13 Nov 2007
Android's VM
Or <jwz>I, for one, welcome our new virtual machine overlords</jwz>
A very interesting theory on why Google created a new VM for Android instead of using an existing VM:
Dalvik is a virtual machine, just like Java's or .NET's.. but it's Google's own and they're making it open source without having to ask permission to anyone (well, for now, in the future expect a shit-load of IP-related lawsuits on this, especially since Sun and Microsoft signed a cross-IP licensing agreement on exactly such virtual machines technologies years ago... but don't forget IBM who has been writing emulation code for mainframes since the beginning of time).
But Android's programs are written in Java, using Java-oriented IDEs (it also comes with an Eclipse plugin)... it just doesn't compile the java code into java bytecode but (ops, Sun didn't see this one coming) into Dalvik bytecode.
So, Android uses the syntax of the Java platform (the Java "language", if you wish, which is enough to make java programmers feel at home and IDEs to support the editing smoothly) and the java SE class library but not the Java bytecode or the Java virtual machine to execute it on the phone (and, note, Android's implementation of the Java SE class library is, indeed, Apache Harmony's!)
With this VM, they managed to not depend on Sun terms for the future of the language and the VM or be bound by any definitions of the Java language. It is worth reading the entire article.
Once the source code for Android is released, it would be interesting to look into integrating Mono wiht it. It should already run on it, as its just Linux. What would be interesting is continuing to use C# to write code for it.
Some ideas that have been bounced around in the mono channels recently include:
- CIL to Dalvik recompiler: Translate CIL bytecodes into Dalvik ones, like (like Grasshopper does) and provide a class library add-on.
- DalvikVM: Implement a VM similar on top of Mono that can run Dalvik bytecodes side-by-side with other CIL code. This would be similar to the IKVM approach: a JavaVM for CIL.
- Dalvik Support in Mono: Paolo suggested to add support to the Mono VM to have a Dalvik loader and turn the Dalvik instructions into the internal Mono IR (the rest at that point would be shared).
- D/Invoke: Add support to the Mono VM to transparently call code into another VM. Very much along the lines of P/Invoke or COM's it-just-works support.
Looking forward to the release.
Posted on 13 Nov 2007
On parsing integers: Jeft Stedfast's Beautiful Code
While the world is debating what is the proper object oriented and syntactic decoration for another wrapper around getElementById we back in Mono-land were coping with a bug related to parsing integers.
In the CLI the original API to parse integers threw exceptions when an overflow was detected. So if you tried to parse a value that is too large to fit on an int, you would get an overflow exception. This is trivial to implement in C# because you just write the parser code more or less like this:
int value, digit; ... value = checked (value * 10 + digit);
If the result for the expression value * 10 + digit the JIT just throws. Beautiful.
This is great as long as your input is error-free, but if you are going to cope with lots of errors, you are going to be coping with a lot of exceptions. And throwing and catching exceptions is consideraly slower than returning an error code. So with .NET 2.0, a new family of methods was introduced, something like this: bool Int32.TryParse (string value, out int result).
The idea here is that instead of raising exceptions left and right we instead try to parse the value, and if the value overflows we just return an error condition.
A simple approach is to use a type that is bigger than the type you are parsing and you just check the boundaries for errors, for example, a byte could use an int:
int value; value = value * 10 + digit; if (value < Byte.MinValue || value > Byte.MaxValue) // error.
The downside with this is that parsing 32-bit ints requires 64-bit longs. This alone is quite expensive as 64-bit operations on 32-bit machines take many more instructions, consume more registers and produce slow code for a very common case. For the 64-bit case, things are worse, since there is no 128-bit longs in .NET, which means that we have to either come up with something clever, or you need to do checked expressions (like before), use try/catch and return an error on the catch handler. Very suboptimal.
The ideal situation is to do the parsing with the data type at hand (use an int for int parsing, a long for long parsing) and catch the overflow before it causes a problem.
Without going into the embarrassing details (which anyone with an inclination to point fingers can do) recently we had to rewrite these routines and Jeff Stedfast came to the rescue with two beautiful routines: one to parse signed integers, and one to parse unsigned integers in C.
His routines are beautiful because they are able to parse a 32-bit int in a single loop, only using 32-bit ints; And 64-bit ints in a single loop, only using 64-bit longs.
His routines were for C code, but variations of these rewritten for C# are now part of our runtime (they will ship as part of Mono 1.2.6).
These routines have a very clever way of coping with overflows.
Posted on 13 Nov 2007
Undoing Bush
Joseph Stiglitz discusses the Economic Consequences of Mr. Bush. Looking back at seven years of mistakes, a great big-picture summary of what went wrong and why, and the damage these policies have inflicted in the US.
Harper's Magazine ran a series of essays on how to fix the mess left behind in Undoing Bush: how to repair eight years of sabotage, bungling, and neglect.
Posted on 10 Nov 2007
Mono Bug Days
On Monday and Tuesday (November 5th and 6th) we want to spend some time triaging, prioritizing and applying easy fixes to Mono from Bugzilla.
We will be on irc.gnome.org on the channel #monobugday on Monday and Tuesday going over various Mono components.
Our entry point is: http://www.mono-project.com/Bugs.
There is a lot of low-hanging fruit that could be easily fixed in Mono, bugs that are invalid, bugs that are missing information, bugs that needs owners, bugs that need confirmation and patches that have been waiting on the bug tracking system to be applied.
I have zero experience running a bug day and am not sure quite how to run this on Monday, if you have some experience, feel free to drop by, or send your comments.
Posted on 03 Nov 2007
FastCGI support for Mono's ASP.NET
 Brian Nickel worked on extending our hosting
server for ASP.NET applications (XSP) to support FastCGI.
Robert Jordan today integrated his Summer of Code project into
the main distribution for XSP.
Brian Nickel worked on extending our hosting
server for ASP.NET applications (XSP) to support FastCGI.
Robert Jordan today integrated his Summer of Code project into
the main distribution for XSP.
Until today developers had two options to host ASP.NET applications with Mono: mod_mono (using Apache) or using a standalone, minimalistic HTTP 1.0 server (the xsp command).
XSP provides the Mono.WebServer.dll ASP.NET application hosting library (controls application domains, starts up new instances of HttpApplication, configures and most importantly implements the communication endpoint for HttpWorkerRequest). Mono.WebServer.dll is not very useful on its own as it does not actually implement the HTTP protocol.
For Mono.WebServer.dll to actually be useful, it is necessary to write an HTTP front end for it. Something that speaks the protocol and passes on the request to the application hosting interface.
Most setups today look like this:
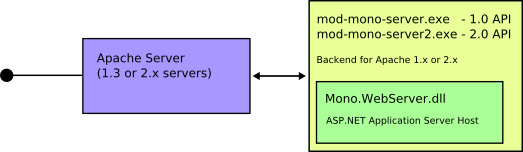
You just have to imagine the "Internet" on the left side (TODO: get a cloud picture, and copy-paste it).
Some courageous people use our test server (xsp) which merely implements HTTP 1.0 and has no configuration options (other than the port to listen to):

Courageous because really, there is not much other than serving files and requests in that server and it is limited to HTTP 1.0.
With Brian's setup, we now add this to the family:
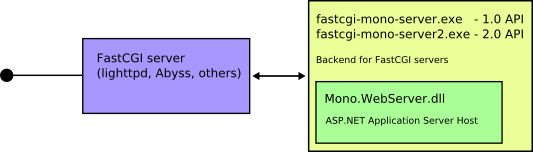
From the FastCGI and Mono Documentation:
The FastCGI Mono Server was developed as part of the 2007 Google Summer of Code with the goal of increasing the availablity of ASP.NET and simplifying configuration. Requiring as little as zero command line options and supporting a large number of servers, the FastCGI Mono Server makes it simple to include ASP.NET on your server.
Documentation on how to configure the FastCGI support for various servers is available here (In particular lighttpd).
This code is available now from our SVN Repository. This should be available on Mono 1.2.6.
Thanks to Brian for writing this nice code and Robert for integrating this into trunk and Marek for his ongoing maintenance of the ASP.NET stack.
Now, who does one have to bribe to get early access to the ASP.NET MVC bits around here or get invited to the ASP.NET SDRs ;-)
Posted on 30 Oct 2007
Mono Versioning
A common problem that I face is explaining to people the current situation of Mono. This is a problem of our own creation when we sketched the major milestones for Mono.
When we originally plotted the course for the Mono Roadmap things looked pretty simple, they were roughly like this:
Mono 1.0:
- Ship the VM 1.0
- Ship the C# 1.0 compiler
- Ship System, Xml, Data, Drawing Web and Web.Services
- Gtk# and friends.
Mono 2.0:
- Upgrade VM to 2.0
- Upgrade compiler to 2.0
- Upgrade libraries to 2.0
- Add Windows.Forms
- Ship Gtk# 2
- Favorite extra stuff (debugger, compacting GC, internal embedding API upgrade)
As you can see, we intended our versioning scheme to track the major Microsoft releases to expedite explanations of what level of APIs Mono supported. So Mono 1.x would be roughly .NET 1.x, Mono 2.x would be roughly .NET 2.x, Mono 3.x would be roughly 3.x and so on.
There is a bit more than just tracking the API, as you can see, there are really two dimensions to what we wanted to call Mono 2.0:

One dimension is the 2.0 compatibility with .NET, and another one has some internal goals of ours. For example, we considered that 2.0 was a good time to break the embedding API for the runtime and also to release the compacting collector.
Complications
There were a few factors that started to complicate our numbering scheme:
- Our Windows.Forms implementation was lagging behind other class libraries (as writing a Winforms control requires much more work than say a Web Control).
- Our desire to implement some major optimizations and improvements in the VM (improved code generation, AOT for 2.x, compacting garbage collection, switch to eglib-based public APIs, change in the embedding API).
- Generics being a requirement for a lot of the 2.0 work that was necessary.
- Microsoft releasing .NET 3.0 which was really just a new set of libraries that just ran on top of 2.0 (we track these in a separate project, called project Olive).
- Microsoft releasing .NET 3.5 which is the actual upgrade to 2.0.
- Some areas would be developed faster than others: sometimes this was due to planning, lack of planning, or big boosts in external contributions (for example, Mainsoft contributed extensively to making ASP.NET 2.0 and ADO.NET 2.0 happen, and they have been shipping their Grasshopper product since ~May).
- We might not support the full API for a given assembly: there might be some features that do not make sense on Linux or features that will never be implemented (like System.Management).
By the time we shipped our Mono 1.2 last year, the problems with the simple versioning numbers started to show. Mono 1.2 included many features from 2.0:
- C# 2.0.
- Generics support in the VM.
- A lot of the 2.0 support in the class libraries. (core, XML, Data and ASP.NET was almost done).
- Support for Windows.Forms 1.0.
Almost a year has passed and we are about to release Mono 1.2.6, six releases after Mono 1.2. Compared to last year's Mono, this upcoming release is a major upgrade, we have since:
- Completed most of the 2.0 support, including:
- Completed C# 2.0.
- Completed ASP.NET 2.x (modulo WebParts).
- Completed ADO.NET 2.x.
- Most of Windows.Forms 2.0 (about 80% of it at this point).
- Implemented most of C# 3.0 (few tidbits missing).
- Implemented LINQ, and LINQ to XML (.NET 3.5).
- Implemented some other bits from .NET 3.5
- A Visual Basic.NET compiler, and its runtime.
- Added a Silverlight toolchain (.NET 2.1).
- Added COM/XPCOM support to Mono.
From an API perspective, with the exception of Windows.Forms 2.0 we have pretty much completed the 2.0 support (what remains to be done is tracked here for the core and here for winforms).
In addition, some bits from 3.5 are being shipped in this upcoming version.
Since we continue to ship updated versions of Mono every 8 to 10 weeks we have only felt that we needed to update the smallest version number (1.2.6 is our upcoming release) each time.
My concern is that 1.2.xx does not really convey the feature set in Mono and some people get the wrong impression of where Mono is at. This problem is made worse because we have been using the simplified numbering scheme for years.
Just today someone emailed me asking when ASP.NET 2.0 will be released, another person asked about ASP.NET AJAX (supported in SVN, and in the upcoming 1.2.6).
Options
We are looking for a creative solution to this problem.
Without using Mono versions, these are roughly the upcoming milestones:
- Mono A: Estimated 3-4 months of work.
- The core 2.0 done + ASP.NET 2.
- 2.0 profile (minus Winforms) becomes officially supported.
- Mono B: Estimated 6-9 months of work.
- Windows.Forms 2.0 complete.
- Mono C: 9+ months.
- When the Compacting GC is done.
- Make the runtime embedding API changes here.
- Mono D: 9+ months.
- When the new IR/optimization framework is ready
- Mono E: 6-9 months of work.
- When System.Core and other 3.5 libraries are finished; maybe we could even split this up in chunks.
- Mono F: 12 months of work, Silverlight security features:
- New security system (done).
- StackOverflow protection (done).
- Complete the Verifier.
- Harden the Mono loader (for Silverlight).
- Full runtime security audit.
The order of the above releases is not necessarily the one listed above, and I used letters to avoid discussing the actual release numbers. Three of those (C, D and F) are difficult to come up with an estimate now.
Massi advocate a model where for large Mono upgrades (ABI changes, like the GC and the runtime API change) we change the major version.
This would mean that we could ship a Mono 1.4 at the time that the "core" 2.0 is done; A Mono 1.6 when Winforms 2.0 is done; A Mono 1.8 when the 3.5 APIs are ready; and Mono 2.0 when we do the GC changes. This proposal does not fix the confusion problem with "1.x" though.
Marek has a slightly modified proposal: when we ship 2.0 minus winforms we call it Mono 1.8; Mono 2.0 includes Winforms, GC, ABI breakage; Mono 2.2 includes new optimization framework;
Jonathan suggest that we could use the major version number to document what is the version number that we feel we can officially support. 2.0 means "2.0 minus Winforms" with an upcoming 2.2 version with Winforms support and 3.5 thrown in the middle at some point (you will notice that the Olive/3.0 discussion is not part of this decision making).
Thoughts? email them to the devel group and CC me ([email protected]).
Posted on 29 Oct 2007
DB_LINQ now MIT X11
George Moudry from the DB_LINQ team has just emailed me to inform me that his multi-database LINQ implementation for .NET is now MIT X11 licensed!
Posted on 28 Oct 2007
Rob Conery Joins Microsoft
Wow. Rob Conery, the author of SubSonic has accepted a job to work for Microsoft. These are the highlights:
- He will continue to work on Subsonic, paid by Microsoft.
- Subsonic will remain open source.
- Rob will continue doing his SonicCasts.
- Subsonic will be playing an important role on ASP.NET's new MVC framework.
Congratulations!
Now only Jon and Jeff remain independent after Mix 07.
[from Phil Haack].
Posted on 27 Oct 2007
OpenSource LINQ providers
Microsoft upcoming .NET 3.5 and C# 3.0 have support for Language Integrated Queries (LINQ). This gives C# and VB users a SQL-like syntax right in the language to access databases directly. For example, this is now valid C#:
public void Linq1() {
int[] numbers = { 5, 4, 1, 3, 9, 8, 6, 7, 2, 0 };
var lowNums =
from n in numbers
where n < 5
select n;
Console.WriteLine("Numbers < 5:");
foreach (var x in lowNums) {
Console.WriteLine(x);
}
}
For more samples, check the 101 LINQ Samples.
There are a number of LINQ providers for different kinds of sources. For example, there is a built-in provider for things like arrays, collections and IEnumerables.
A more useful sample comes from Don Box, this is a program to extract the top ten read articles from an Apache log file file:
var regex = new Regex(@"GET /ongoing/When/\d\d\dx/(\d\d\d\d/\d\d/\d\d/[^ .]+)");
var grouped = from line in ReadLinesFromFile("logfile.txt")
let match = regex.Match(line)
where match.Success
let url = match.Value
group url by url;
var ordered = from g in grouped
let count = g.Count()
orderby count descending
select new { Count = count, Key = g.Key };
foreach (var item in ordered.Take(10))
Console.WriteLine("{0}: {1}", item.Count, item.Key);
There is another provider for creating and consuming XML data: LINQ to XML. The LINQ distribution comes with a nice sample where many of the samples from the XQuery specification have been rewritten into C# with LINQ with code that is roughly the same size (which sadly, I can not find online to point to).
Luckily, we have implementations for both of these in Mono.
And finally there are providers for databases. Microsoft ships one that will integrate natively with Microsoft SQL.
Unlike the XML and in-memory providers, the SQL providers are more complicated as they need to turn high-level operations into optimized SQL statements. Unlike many object to database mapping systems that produce very verbose SQL statements LINQ is designed to provide a very efficient representation.
The Db_Linq is an open source project to create a LINQ provider for other databases. The project is lead by George Moudry and so far has providers for PostgreSQL, Oracle and Mysql.
George keeps a blog here where you can track the development of DbLinq.
Thanks to Bryan for pointing me out to this fantastic piece of code.
Mono users on Linux will now be able to use LINQ with open source databases from C# (in addition to our in-memory and XML providers).
Currently we are still missing some support in our compiler and our class libraries for this to work in Mono, but this will be a great test case and help us deliver this sooner to developers.
Update: A nice blog entry talks about Parallel LINQ. A version of LINQ that can be used to parallelize operations across multiple CPUs:
IEnumerabledata = ...; // Regular code: var q = data.Where(x => p(x)). Orderby(x => k(x)).Select(x => f(x)); foreach (var e in q) a(e); // Parallelized version, add the "AsParallel" method: var q = data.AsParallel().Where(x => p(x)). Orderby(x => k(x)).Select(x => f(x));
See more details about the above in the Running Queries On Multi-Core Processors article.
Update2: Am not up to speed in the databases vs object databases wars, but am told that there is also a LINQ binding for NHibernate. A sample is here.
Posted on 24 Oct 2007
« Newer entries | Older entries »
Blog Search
Archive
- 2024
Apr Jun - 2020
Mar Aug Sep - 2018
Jan Feb Apr May Dec - 2016
Jan Feb Jul Sep - 2014
Jan Apr May Jul Aug Sep Oct Nov Dec - 2012
Feb Mar Apr Aug Sep Oct Nov - 2010
Jan Feb Mar Apr May Jun Jul Aug Sep Oct Nov Dec - 2008
Jan Feb Mar Apr May Jun Jul Aug Sep Oct Nov Dec - 2006
Jan Feb Mar Apr May Jun Jul Aug Sep Oct Nov Dec - 2004
Jan Feb Mar Apr May Jun Jul Aug Sep Oct Nov Dec - 2002
Jan Feb Mar Apr May Jun Jul Aug Sep Oct Dec
- 2022
Apr - 2019
Mar Apr - 2017
Jan Nov Dec - 2015
Jan Jul Aug Sep Oct Dec - 2013
Feb Mar Apr Jun Aug Oct - 2011
Jan Feb Mar Apr May Jun Jul Aug Sep Oct Nov Dec - 2009
Jan Feb Mar Apr May Jun Jul Aug Sep Oct Nov Dec - 2007
Jan Feb Mar Apr May Jun Jul Aug Sep Oct Nov Dec - 2005
Jan Feb Mar Apr May Jun Jul Aug Sep Oct Nov Dec - 2003
Jan Feb Mar Apr Jun Jul Aug Sep Oct Nov Dec - 2001
Apr May Jun Jul Aug Sep Oct Nov Dec