Love Kucinich
This is just brilliant.
Hope my American friends like Kucinich as much as I do.
Update: Slate covers the health plans. Kucinich is the best.
More Kucinich Awesomeness: New NIE Report Shows Bush Administration Has Once Again Tried To Falsify Grounds For A War With Iran.
Posted on 04 Dec 2007
Mono on OSX, Win32
In general, the focus of the Mono team is on Unix system, and more specifically for open source versions of Unix (Linux and BSD) but we still provide provide some support for Win32, Solaris and OSX even if they are proprietary and OpenSolaris (even if its licensed for mininal collaboration and cross pollination with Linux).
In general, our cross platform story has suffered a little bit when it comes to GUI toolkits: our Windows.Forms implementation works with X11, but Mac users really want to run a native version of it, without requiring an X server.
Gtk# suffers from the same problem: it works on X11, OSX and Windows, but on OSX it requires the X11 driver which is suboptimal.
In general, I do not like to support proprietary operating systems, but in the particular case of OSX, there is enough of a user-base that it made sense to bend backwards for the sole purpose of increasing the contributor and user bases.
At the Mono Summit we outlined our new strategy for OSX:
- Our Windows.Forms now has a native OSX back-end. Mono 1.2.6 will ship with it, and Mono 1.2.7 will ship with several upgrades (some already on SVN) that will make Windows.Forms applications run even better on OSX.
- We will distribute Imendio's Gtk+ for OSX and Gtk# as part of our runtime. It has now reached a maturity point that allows applications like MonoDevelop to run natively (without X11).
- We will distribute MonoDevelop for OSX users as a pre-compiled package, and we will provide support for it.
- MonoDevelop will also be ported to Windows. The work necessary to port MonoDevelop to OSX is also going to help the port of MonoDevelop to Windows. This should be useful for people that are building Gtk#-centric applications on Windows. For other uses Visual Studio and SharpDevelop will continue to be better IDEs to use.
We will support the following, but only as a lower priority, and work on them will be preempted by other needs in Mono:
- We will support Objc-Sharp for those that need bridges between Objective-C and Mono. But
- We will depend on the community, and provide some assistance to those that rather use the CocoaSharp bindings to the native Cocoa APIs.
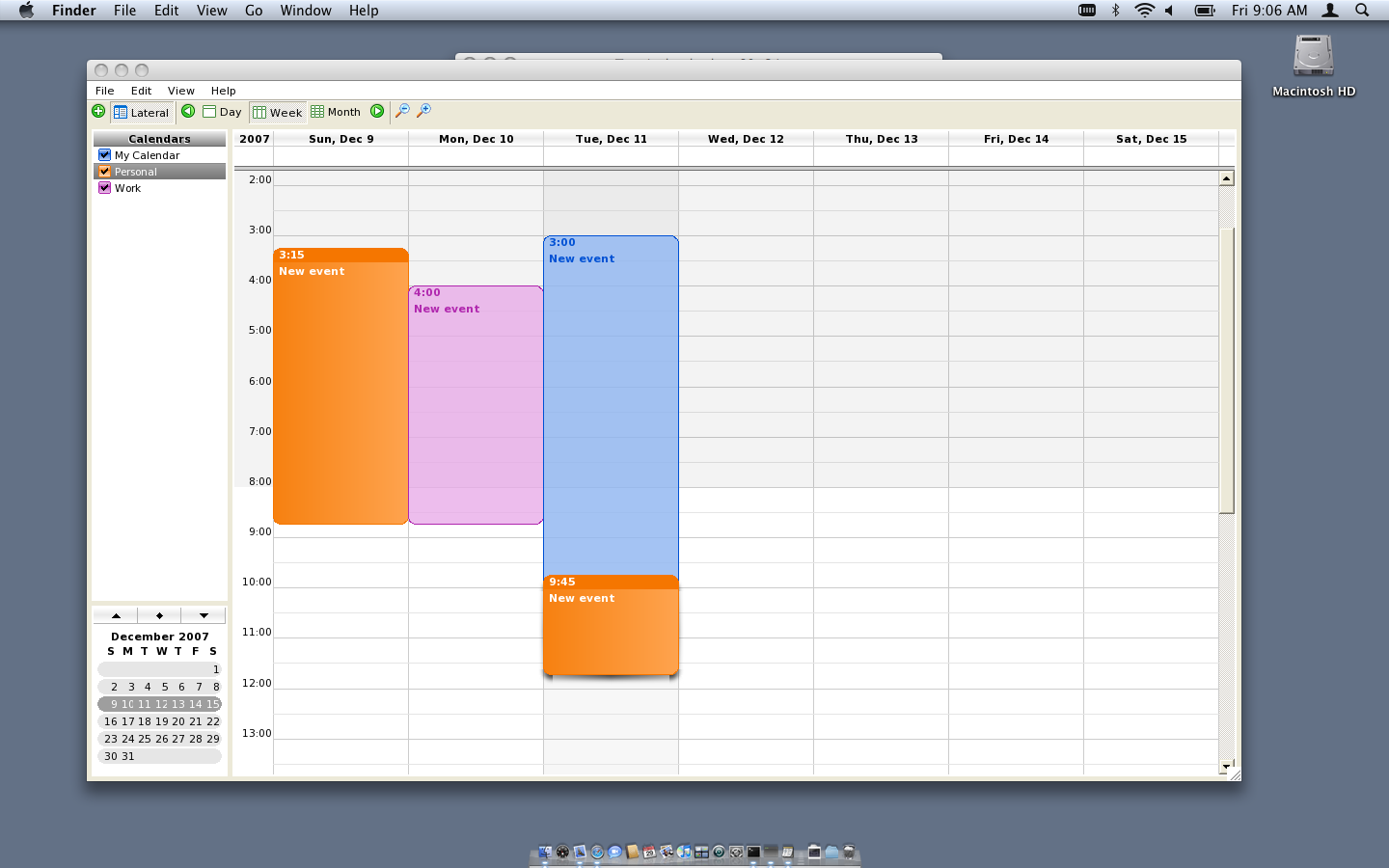
A screenshot of a Windows.Forms app running with the native driver (click for a full shot):
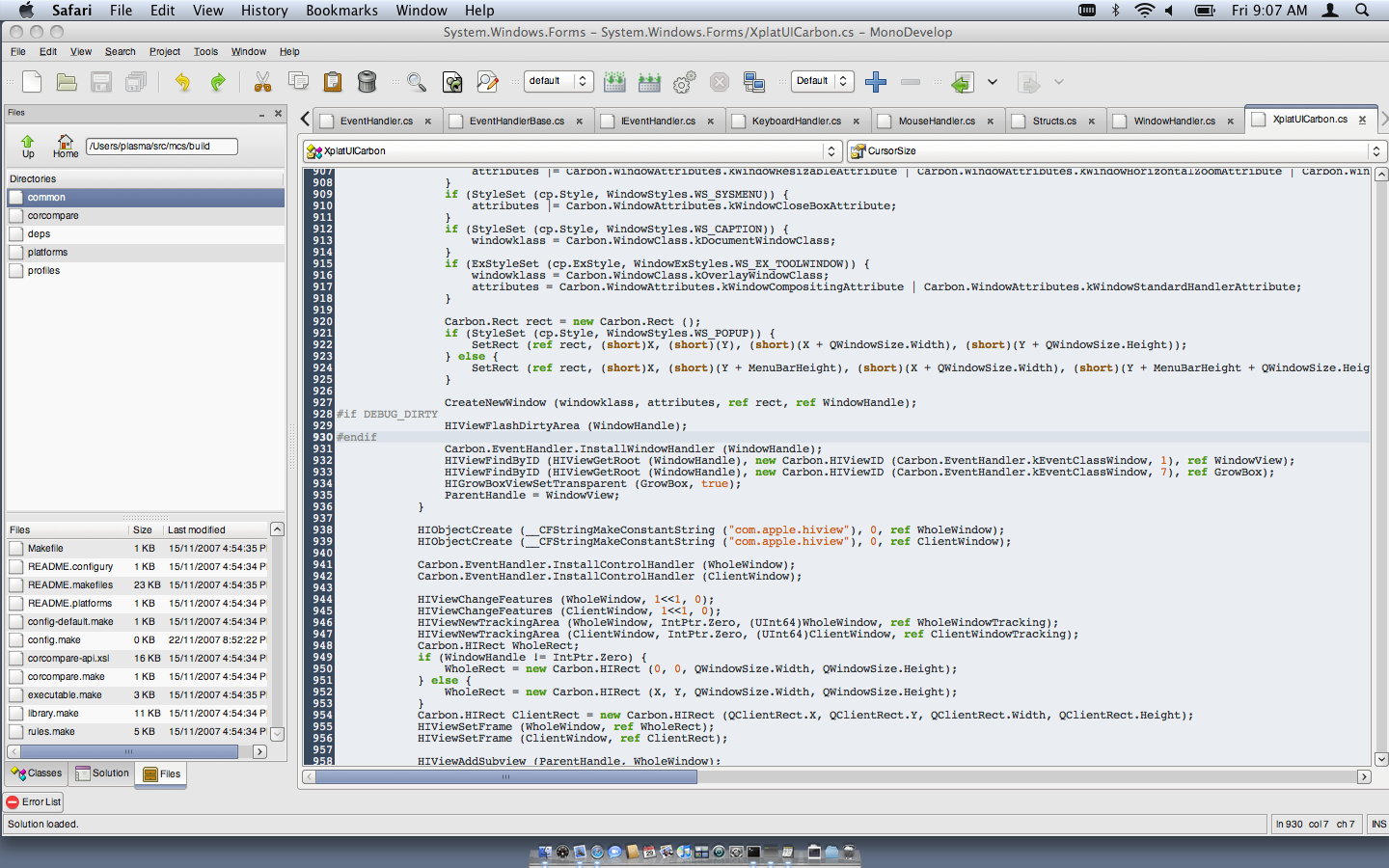
A screenshot of MonoDevelop, our Gtk# based IDE on MacOS with Gtk's native OSX driver:
We are shipping MonoDevelop 1.0 at the end of January, after this, we will start work on the debugger integration into MonoDevelop (the most requested feature) and we will also add support for developing Silverlight applications with it.
At the Mono Summit, we got Moonlight running on MacOS X (including desklets!) which means that our Silverlight designer (currently called LunarEclipse) will be available on MonoDevelop on OSX. But we will not support Moonlight on the browser on Safari or Firefox on OSX as you can run Microsoft's edition there.
Posted on 02 Dec 2007
The Mono Summit is Over
 The summit was fantastic. The first two days we
did a bit of internal planning for the project (we had Novell
employees and contributors that day).
The summit was fantastic. The first two days we
did a bit of internal planning for the project (we had Novell
employees and contributors that day).
Although I had originally wanted to have as much empty space as possible to do some more Unconference style presentations, we probably had too much structure in place. At least we had some large holes between presentations for people to talk to each other (except that not one talk finished on time, which meant that we were always a few hours later to end the day).
The event was supposed to end every day at 17:45pm, but most of us barely left the place before 9pm (which was nice of them, to keep the place open for us until late). Followed by a late-dinner in Madrid, and a then some socializing in the hotel lobby or nearby bars turned into four hours of sleep every night.
Thanks to everyone that made this happen, and for our Ismael Olea who provided our logistic support at the event every day and Alejandro S�nchez that got us this beautiful venue in Madrid.
I hope that all the attendees got to talk to the team members; I know that many of you did, and I hope that we fixed your issues, or we came up with a solution for your issues.
Posted on 02 Dec 2007
XML Conference
Next week I will be attending the XML Conference here in Boston. Am looking forward to the opening keynote on Monday by Douglas Crockford.
My friend Rich Saltz invited me to talk about Moonlight: our open source implementation of Silverlight on Linux (Wednesday).
On Tueday I will talk about our efforts to support both ODF and OOXML at Novell in our edition of OpenOffice.
Posted on 02 Dec 2007
Botijos in New York City
 My
friend Karla
Frechilla will be presenting her artwork in New York City
starting this Saturday until the 15th.
My
friend Karla
Frechilla will be presenting her artwork in New York City
starting this Saturday until the 15th.
There will be an opening reception on Tuesday December 4th from 6 to 8 pm at Jadite Galleries 413 W 50th St in New York City.
She will be presenting her Botijos as well as some of her paintings.
Posted on 30 Nov 2007
Generics Memory Usage
Aaron walked into my office today to get some some feedback on some implementation detail for his new listview in Banshee.
Before he left the office he said something like, but not necessarily "In some Microsoft blog someone commented that I should not use generics for small arrays of value types" (see Update at the bottom).
So we decided to measure with a trivial program the memory consumption for storing small arrays with and without generics with Mono 1.2.5 and Mono 1.2.6.
Storing 8 megs of ints (32-megs of data) on an array of objects has a high overhead: the actual data, the box, the object lock which means that you end up using about 21.5 bytes per int:
object [] e = new object [size]; for (int i = 0; i < size; i++) e [i] = 1;
With a generic array, you are as close as possible to a real array and you only consume 38 megs of ram (this is the full process size, the 32 meg array plus the Mono runtime, JIT, etc), the following sample ensures that am not using a regular int array, but an instantiated generic class with ints:
public class D<T> {
public T [] t;
public D (int size)
{
t = new T [size];
}
}
D<int> d = new D<int> (size);
for (int i = 0; i < size; i++)
d.t [i] = 1;
The regular collection consumes 178 megs of ram, while the generics collection consumes 38 megs of ram (when running with Mono).
I was a bit shocked about the 178 megs of ram used by regular object wrappers, so I wrote the equivalent for Java, to see how they fared compared to Mono:
Object [] x = new Object [8*1024*1024];
for (int i = 0; i < 8*1024*1024; i++)
x [i] = new Integer (i);
Java uses 248 megs of ram, so it is chubbier than regular C# at 30 bytes per boxed int on average (this was with Sun's Java 1.6.0, maybe there are newer versions, but thats what I got on my system).
I got no Java/generics skills to implement the above with Java, but since Java does not really have generics at the VM level (they are implemented purely as a language-level feature), I do not think that the numbers would be significantly different).
Mono 1.2.6 also introduces a number of memory reduction features for generics that reduce the size of our interfaces. When using generics, in 1.2.5 on a List<int> case we were generating a lot of useless stuff:
IMT tables size: 7752
IMT number of tables: 102
IMT number of methods: 2105
IMT used slots: 872
IMT colliding slots: 486
IMT max collisions: 27
IMT methods at max col: 134
IMT thunks size: 19060
With the
upcoming
1.2.6 release the memory savings for the metadata kept
resident by the runtime are also significant:
IMT tables size: 7752
IMT number of tables: 102
IMT number of methods: 4
IMT used slots: 2
IMT colliding slots: 1
IMT max collisions: 3
IMT methods at max col: 3
IMT thunks size: 34
There is still an issue of locality. Using the boxing collections has the advantage that the same code is shared across all possible types. The generic versions on the other hand get their own JITed versions of every method involved (at least today).
You can track Mark's progress to change this as he continues with our implementation for generic code sharing.
Summary: From a memory consumption point of view, the bottom line is: if you are storing value types (non-object values like ints, longs, bools) it is better to use generic collections (System.Collections.Generic) than using the general-purpose collections (System.Collections). If you are just going to store references to objects, there is really no difference.
Update: The comment was from Rico Mariani, and the source of the confusion was:
List<T> offers generally better performance than ArrayList as well as type safety. We recommend using List<T> over ArrayList always if T is a reference type. If T is a value type there is additional cost assocated with creating a specialized version of List<T> for that value type. When T would be a value type we recommend List<T> if the savings in boxing is greater than the cost of the additional code -- this tends to happen if you store about 500 elements across all your List<T> objects.
OK, so the confusion is not that it might be worse for value types, but that the JIT will have to generate specific instantiations of generic methods (Insert for example) based on the parameter type.
So the JIT generates separate code for a List.Insert of int and for a List.Insert of long. Considering the savings for even small apps, I will go with "Go wild with the value types" myself as the code for the collection code is really small.
Posted on 21 Nov 2007
Javascript Decompressor Roundup
Thanks to everyone that emailed me answers to the Javascript decompressor issue. This is a reply in case other people are looking at ways of de-obfuscating or have to debug some compressed Javascript code.
I included the names of the nice folks that emailed me, and some comments for those that I actually tried out.
Some annotations:
- [CMD] works from the command line, my favorite kind.
- [WEB] Provides a web UI.
- [GUI] GUI
- [SOURCE] comes with source code.
- [WINDOWS] Windows-only
Here they go:
- [WEB, CMD, SOURCE] Beautify is a PHP-based, server-side decompressor. This was the one I used to debug some of the problems we were having, and the results are very good. Source code is available for you to run on your local server, or you can reuse it from the command line (some assembly required for command-line use).
- [CMD,
SOURCE]Qooxdoo's
pretty printer written in Python (Fabian Jakobs,
Sebastian Werner), to use:
$ INSTALL_PATH/frontend/framework/tool/modules/compiler.py file.js
Alternatively, you can get only the pretty printer from SVN:
$ svn co https://qooxdoo.svn.sourceforge.net/svnroot/qooxdoo/trunk/qooxdoo/frontend/framework/tool/ $ modules/compiler.py -w originalFile.js
- [WEB, SOURCE] Beautify.aspx. Get the source code as the link from their web page is broken (Jokin Cuadrado, Steven Coffman).
- [GUI, WINDOWS] A Plug-in for Fiddler: Fiddler is a Windows HTTP debugger, if you are using Windows and Fiddler this plugin might be for you (Jokin Cuadrado, Steinar Herland).
If you are a VIM user, this VIM script provides Javascript indentation. but it seems like a lot of work for general-purpose decompression of javascript (Kjartan Maraas).
If you feel that none of the above is good for you and you want to prepare for your interview at Google, Jeff Walden suggests a hard-core approach:
One of the less well-known aspects of SpiderMonkey, Mozilla's C JavaScript engine, is that it includes a decompiler which translates from SpiderMonkey bytecode to JavaScript (most people only use it the other way around). You can see it at work any time you convert a function to a string. Most JavaScript engines, when asked to convert a function to a string, do one of two things: return the exact source text (I believe IE does this, but I haven't double-checked), or return a string provides the minimum ECMAScript requires -- that the string have the syntax of a function declaration, i.e. that it be be evaluable to create a function (I think this is what Safari does). SpiderMonkey's choice to eliminate the overhead of storing source text after converting means that it can't do the former, and the latter is unpalatable from a developer standpoint. Instead, it decompiles the bytecode back to a JavaScript string representing the function as exactly as possible, while at the s ame time formatting the decompiled source to be reasonably readable. How would you use SpiderMonkey to reformat obfuscated source? First, you get a copy of SpiderMonkey:export CVSROOT=:pserver:[email protected]:/cvsroot cvs co mozilla/js/src cd mozilla/js/src make -f Makefile.ref clean && make -f Makefile.ref # work around broken dependency system.obj/js # to run the interpreter Next, you dump the JS code you want to reformat into a function, and you have SpiderMonkey pretty-print it:
echo "function container() {" > obfuscated.js cat file-to-clean-up.js >> obfuscated.js echo "} print(container.toString());" >> obfuscated.js path/to/js -f obfuscated.jsSpiderMonkey will then print the container function's string representation, adjusting indentation and such to create a readable, if still name-obfuscated, version.
A couple things to know about this: first, SpiderMonkey doesn't pretty-print functions found in expression context:
(function() { print("this won't get cleaned up"); })(); call_method(function() { print("this will probably be crunched to one line"); print("not pretty-printed"); });These examples are converted (once stripped of the containing function) to:
(function () {print("this won't get cleaned up");}()); call_method(function () {print("this will probably be crunched to one line");print("not pretty-printed");});The former pattern's become fairly common for reducing namespace collisions (unfortunately for the decompiler), and the latter's become more popular as the functional aspects of JavaScript have been more played up recently in libraries. For now at least I think you just have to tweak the original source file to fix these problems. The decompiler could do a better job on these given some changes, but I don't see this happening any time soon. The decompiler is generally agreed to be one of the hairiest and least-well-understood pieces of code in SpiderMonkey, and people don't touch it that often.
Incidentally, the decompiler is also what allows SpiderMonkey to give the informative error messages it gives when your code throws an uncaught exception; the error messages I've seen in any other JavaScript interpreter are woefully less useful than the ones SpiderMonkey gives you using the decompiler.
Posted on 16 Nov 2007
RayTracing in one LINQ statement
 Through Don
Syme's blog I read
about Luke Hoban
moving from the C# team at Microsoft to the F# team, I did not
know about Luke's blog until now, it is a fantastic collection
of cool C# 3 nuggets.
Through Don
Syme's blog I read
about Luke Hoban
moving from the C# team at Microsoft to the F# team, I did not
know about Luke's blog until now, it is a fantastic collection
of cool C# 3 nuggets.
One of the things that impressed me the most is a recent sample he posted.
Luke implements
a RayTracer in one line LINQ code. This test is insane
(and sadly, our C# compiler is not yet able to handle that
kind of complexity yet for LINQ statements). I reproduce it
here (directly copy-pasted from Luke's blog):
var pixelsQuery = from y in Enumerable.Range(0, screenHeight) let recenterY = -(y - (screenHeight / 2.0)) / (2.0 * screenHeight) select from x in Enumerable.Range(0, screenWidth) let recenterX = (x - (screenWidth / 2.0)) / (2.0 * screenWidth) let point = Vector.Norm(Vector.Plus(scene.Camera.Forward,
Vector.Plus(Vector.Times(recenterX, scene.Camera.Right), Vector.Times(recenterY, scene.Camera.Up)))) let ray = new Ray { Start = scene.Camera.Pos, Dir = point } let computeTraceRay = (Func<Func<TraceRayArgs, Color>, Func<TraceRayArgs, Color>>) (f => traceRayArgs => (from isect in from thing in traceRayArgs.Scene.Things select thing.Intersect(traceRayArgs.Ray) where isect != null orderby isect.Dist let d = isect.Ray.Dir let pos = Vector.Plus(Vector.Times(isect.Dist, isect.Ray.Dir), isect.Ray.Start) let normal = isect.Thing.Normal(pos) let reflectDir = Vector.Minus(d, Vector.Times(2 * Vector.Dot(normal, d), normal)) let naturalColors =
from light in traceRayArgs.Scene.Lights let ldis = Vector.Minus(light.Pos, pos) let livec = Vector.Norm(ldis) let testRay = new Ray { Start = pos, Dir = livec } let testIsects = from inter in from thing in traceRayArgs.Scene.Things select thing.Intersect(testRay) where inter != null orderby inter.Dist select inter let testIsect = testIsects.FirstOrDefault() let neatIsect = testIsect == null ? 0 : testIsect.Dist let isInShadow = !((neatIsect > Vector.Mag(ldis)) || (neatIsect == 0)) where !isInShadow let illum = Vector.Dot(livec, normal) let lcolor = illum > 0 ? Color.Times(illum, light.Color) : Color.Make(0, 0, 0) let specular = Vector.Dot(livec, Vector.Norm(reflectDir)) let scolor = specular > 0 ? Color.Times(Math.Pow(specular, isect.Thing.Surface.Roughness), light.Color) : Color.Make(0, 0, 0) select Color.Plus( Color.Times(isect.Thing.Surface.Diffuse(pos), lcolor), Color.Times(isect.Thing.Surface.Specular(pos), scolor)) let reflectPos = Vector.Plus(pos, Vector.Times(.001, reflectDir)) let reflectColor =
traceRayArgs.Depth >= MaxDepth ? Color.Make(.5, .5, .5) : Color.Times(isect.Thing.Surface.Reflect(reflectPos), f(new TraceRayArgs(new Ray { Start = reflectPos, Dir = reflectDir }, traceRayArgs.Scene,
traceRayArgs.Depth + 1))) select naturalColors.Aggregate(reflectColor, (color, natColor) => Color.Plus(color, natColor)))
.DefaultIfEmpty(Color.Background).First()) let traceRay = Y(computeTraceRay) select new { X = x, Y = y, Color = traceRay(new TraceRayArgs(ray, scene, 0)) }; foreach (var row in pixelsQuery) foreach (var pixel in row) setPixel(pixel.X, pixel.Y, pixel.Color.ToDrawingColor());
Although the above is pretty impressive, you might want to read about Luke's history of writing ray tracers as test cases for a new language (I write the factorial function, Luke writes Ray Tracers). His original sample from April goes into the details of how to define the scene, the materials and the objects and is useful to understand the above LINQ statement.
The full source code (includes the support definitions for defining the Scene and materials) is available here.
The original code (not LINQ-ified) is available here.
Posted on 16 Nov 2007
Javascript decompressors?
Recently we have been debugging lots of Javascript from web pages, and the Javascript is either white-space compressed or obfuscated.
Does anyone know of a tool (preferably for Unix) to turn those ugly Javascript files into human readable form?
Am currently using GNU indent which is designed for C programs, but it does a mildly passable job at deciphering what is going on, but it is not really designed to be a Javascript pretty-printer. I would appreciate any pointers.
Posted on 13 Nov 2007
Mono Summit Schedule Published
Jackson
has
published
the Mono
Summit 2007 Program Schedule.
If you are attending, please remember to register.
Posted on 13 Nov 2007
« Newer entries | Older entries »
Blog Search
Archive
- 2024
Apr Jun - 2020
Mar Aug Sep - 2018
Jan Feb Apr May Dec - 2016
Jan Feb Jul Sep - 2014
Jan Apr May Jul Aug Sep Oct Nov Dec - 2012
Feb Mar Apr Aug Sep Oct Nov - 2010
Jan Feb Mar Apr May Jun Jul Aug Sep Oct Nov Dec - 2008
Jan Feb Mar Apr May Jun Jul Aug Sep Oct Nov Dec - 2006
Jan Feb Mar Apr May Jun Jul Aug Sep Oct Nov Dec - 2004
Jan Feb Mar Apr May Jun Jul Aug Sep Oct Nov Dec - 2002
Jan Feb Mar Apr May Jun Jul Aug Sep Oct Dec
- 2022
Apr - 2019
Mar Apr - 2017
Jan Nov Dec - 2015
Jan Jul Aug Sep Oct Dec - 2013
Feb Mar Apr Jun Aug Oct - 2011
Jan Feb Mar Apr May Jun Jul Aug Sep Oct Nov Dec - 2009
Jan Feb Mar Apr May Jun Jul Aug Sep Oct Nov Dec - 2007
Jan Feb Mar Apr May Jun Jul Aug Sep Oct Nov Dec - 2005
Jan Feb Mar Apr May Jun Jul Aug Sep Oct Nov Dec - 2003
Jan Feb Mar Apr Jun Jul Aug Sep Oct Nov Dec - 2001
Apr May Jun Jul Aug Sep Oct Nov Dec